基于梯度的优化方法
我们把要最小化或最大化的函数称为目标函数或准则函数。
多维函数的偏导数
- 二元函数:
:f对x的偏导数,描述固定y时函数值f随x的变化率。
:f对y的偏导数,描述固定x时函数值f随y的变化率。 - 多维函数:,偏导数衡量点x处只有增加时如何变化,。
多维函数的梯度
- 二元函数:
二元函数的梯度:{} - 多维函数:记为,梯度的第i个元素是f关于的偏导数。
= {}
多维函数的方向导数
- 二元函数:
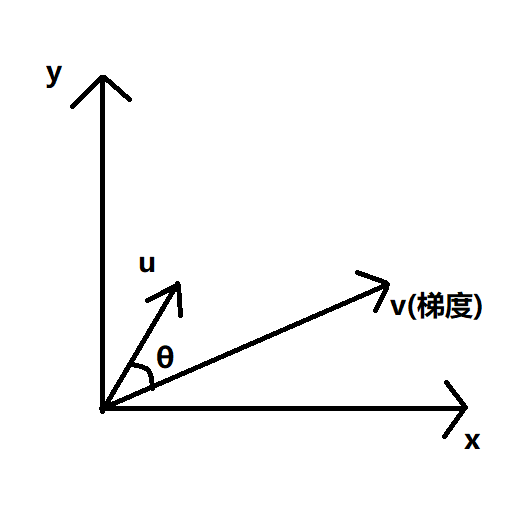
其中v表示的梯度,u为单位向量。在u方向的方向导数,大小为v在u上的投影长度,方向为u。
- 多维函数:在多维情况下,
为了最小化,希望找到使下降的最快的方向,
因此在u与梯度相反时,取得最小,称为梯度下降。梯度下降建议新的点为:
,其中为学习率。
Jacobian和Hessian矩阵
有时需要计算输入和输出都为向量的函数的所有偏导数。如:
,则的Jacobian矩阵为
例如:
有时我们也需要计算二阶导数,二阶导数是对曲率的衡量,当函数有多维输入时,二阶导数也有很多,将其合并成一个矩阵,称为Hessian矩阵。
我们可以通过二阶导数预期一个梯度下降步骤能够表现的多好,在点处作的近似二阶泰勒级数:
,其中是梯度,是点的Hessian。
当学习率为,那么新的点为,代入得:
当为零或者负值时,近似的泰勒级数表明增加将永远使下降,但很大的时候,泰勒级数的近似就不准确,因此需要更启发式的选择。
当为正时,使近似泰勒级数下降最多的最优步长为,
最坏情况下,与最大特征值对应的特征向量对齐,则最优步长为,故在要最小化的函数能用二次函数很好近似时,Hessian矩阵的特征值决定了学习率的量级。
二阶导数测试
二阶导数可以用于确定一个临界点是否是局部极大点,局部极小点,或鞍点,但当时,测试是不确定的。
利用Hessian矩阵的特征值分解,可以将二阶导数测试扩展到多维情况,在临界点处(),我们通过检测Hessian的特征值来判断该临界点是局部极大点,局部极小点,还是鞍点:
- 若Hessian正定,则该临界点是局部极小值点。
- 若Hessian负定,则该临界点是局部极大值点。
- 当所有非零特征值是同号且至少有一个特征值为0时,检测不确定。
当在一个方向上导数增加很快,而在另一个方向上倒数增加很慢,此时梯度下降无法利用Hessian中的信息,不知道导数的这种变化,当函数呈长峡谷壮时,梯度下降法的效率极低。
我们可以利用Hessian矩阵的信息来指导搜索,解决这个问题,其中最简单的是牛顿法。
计算得临界点:
基本思想:对x求导的结果要和x的形状相同。
只利用梯度信息的优化算法称为一阶优化算法,如梯度下降;利用Hessian矩阵的优化算法被称为二阶优化算法,如牛顿法。